PG_Project 1: Text Summarization With Deep Learning
Background
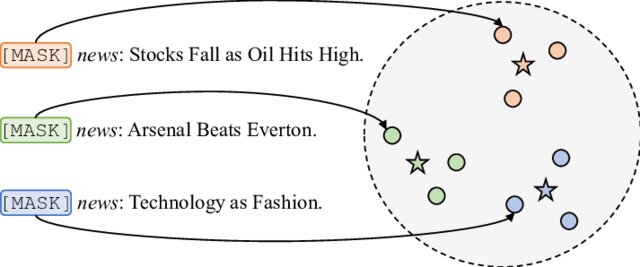
Text summarization is a Natural Language Processing (NLP) task that summarizes the information in large texts for quicker consumption without losing vital information. Your favourite news aggregator (such as Google News) takes advantage of text summarization algorithms in order to provide you with information you need to know whether the article is relevant or not without having to click the link.
Research methods
This project you need to do a simple text summarization task. You need to use Abstractive Text Summarization and packages like newspeper2k and PyPDF2 to convert the text into a format that Python understands. Finally, we’ll use SPaCy to summarize the text with deep learning. Once you understand how text summarization works, you can also try doing the same with audio files that need to be first transcribed to text.
There are two main text summarization methods:
- Extractive Text Summarization – attempts to identify significant sentences and then adds them to the summary, which will contain exact sentences from the original text.
- Abstractive Text Summarization – attempts to identify important sections, interpret the context and intelligently generate a summary.
Suggested procedures
Step 1 - Installing Text Summarization Python Environment
To follow along with the code in this article, you can download and install our pre-built Text Summarization environment, which contains a version of Python 3.8 and the packages used in this post.
Step 2 – Choose A Text Source For Abstractive Text Summarization
The quality, type, and density of information conveyed via text varies from source to source. Textbooks tend to be low in density but high in quality, while academic articles are high in both quality and density. On the other hand, news articles can vary significantly from source to source.
Regardless of where the text comes from the goal here is to minimize the time you spend reading. Thus, we will build a tool that can easily be adapted to any number of sources.
For this example, we will use a news article on a recent global warming study from ScienceDaily as our text source. Feel free to use a different article.
To extract the text from the URL, we’ll use the newspaper3k package:
from newspaper import Article
url = 'https://www.sciencedaily.com/releases/2021/08/210811162816.htm'
article = Article(url)
article.download()
article.parse()
Now, we’ll download and parse the article to extract the relevant attributes. From here, we can view the article text:
article.text

Clearly, this is quite long and dense. This text will serve as our input for the summarization algorithm that we’ll write in the next step.
If your particular application requires extracting text from pdf documents, try out the PyPDF2 package. Alternatively, if you have audio files that need to be transcribed to text, try using the SpeechRecognition package. Once you have the text in a format that Python can understand, you can move on to summarizing it.
Step 3 – Summarizing Text With SpaCy
A human might approach the task of summarizing a document as follows:
- Read the full text
- Understand the concepts being conveyed
- Pick out the most important concepts
- Simplify them in a more concise manner
For a computer to perform the same task, a semantic understanding of the text is necessary. While semantic analysis is possible with current NLP algorithms, it often requires significant computational power and produces results similar in quality to other extractive techniques.
Rather than understanding the text, extractive summarization relies on quantitative metrics constructed from the text itself, without attaching any exogenous meaning. Our approach is to simply:
- Look at the use frequency of specific words
- Sum the frequencies within each sentence
- Rank the sentences based on this sum
Of course, our assumption is that a higher-frequency word use implies a more ‘significant’ meaning. This may seem overly simplistic, but this approach often produces surprisingly good results.
To begin, we’ll first need to import the different packages:
import spacy
from spacy.lang.en.stop_words import STOP_WORDS
from string import punctuation
from heapq import nlargest
We’ll use SpaCy to import a pre-trained NLP pipeline to help interpret the grammatical structure of the text. This will allow us to identify the most common words that are often useful to filter out (i.e. STOP_WORDS) as well as the punctuation (i.e. punctuation). We’ll also use the nlargest function to extract a percentage of the most important sentences. Our algorithm will use the following steps:
- Tokenize the text with the SpaCy pipeline. This segments the text into words, punctuation, and so on, using grammatical rules specific to the English language.
- Count the number of times a word is used (not including stop words or punctuation), then normalize the count. A word that’s used more frequently has a higher normalized count.
- Calculate the sum of the normalized count for each sentence.
- Extract a percentage of the highest ranked sentences. These serve as our summary.
We can write a function that performs these steps as follows:
def summarize(text, per):
nlp = spacy.load('en_core_web_sm')
doc= nlp(text)
tokens=[token.text for token in doc]
word_frequencies={}
for word in doc:
if word.text.lower() not in list(STOP_WORDS):
if word.text.lower() not in punctuation:
if word.text not in word_frequencies.keys():
word_frequencies[word.text] = 1
else:
word_frequencies[word.text] += 1
max_frequency=max(word_frequencies.values())
for word in word_frequencies.keys():
word_frequencies[word]=word_frequencies[word]/max_frequency
sentence_tokens= [sent for sent in doc.sents]
sentence_scores = {}
for sent in sentence_tokens:
for word in sent:
if word.text.lower() in word_frequencies.keys():
if sent not in sentence_scores.keys():
sentence_scores[sent]=word_frequencies[word.text.lower()]
else:
sentence_scores[sent]+=word_frequencies[word.text.lower()]
select_length=int(len(sentence_tokens)*per)
summary=nlargest(select_length, sentence_scores,key=sentence_scores.get)
final_summary=[word.text for word in summary]
summary=''.join(final_summary)
return summary
Note that per is the percentage (0 to 1) of sentences you want to extract. To test it out on the ScienceDaily article, run:
summarize(article.text, 0.05)
The output should look like this:

You can read the complete article for yourself to judge how well this reflects the complete text. However, a summary is already provided by the author at the top of the article. It reads, “Global warming begets more, extreme warming, new paleoclimate study finds. Researchers observe a ‘warming bias’ over the past 66 million years that may return if ice sheets disappear.”
Pretty much spot on, right?
Conclusion
Use Text Summarization And Improve Your Productivity With Python Maximizing your efficiency by minimizing the time you spend reading can have a dramatic impact on productivity. Whether you’re reading textbooks, reports, or academic journals, the power of natural language processing with Python and SpaCy can reduce the time you spend without diluting the quality of information. One of the example Python code is available in GitLab repository.