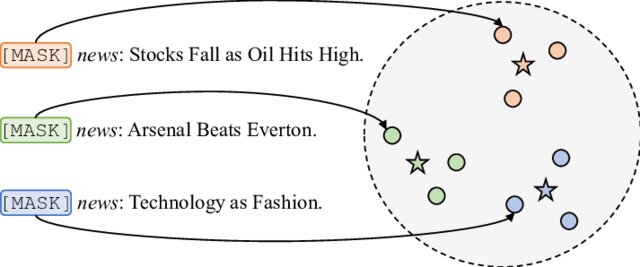
Intention-Preference for Sequential Recommendation
#Hierarchical User Intention-Preference for Sequential Recommendation with Relation-Aware Heterogeneous Information Network Embedding
Abstract:
Existing recommendations usually make recommendations by exploiting the binary relationship between users and items, and assume that users only have flat preferences for items. They ignore the users’ intentions as an origin and driving force for users’ performance. Cognitive science tells us that users’ preference comes from an explicit intention. They firstly have the intention to possess a particular (type of) item(s) and then their preferences emerge when facing multiple available options. Most of the data used in recommender systems are composed of heterogeneous information contained in a complicated network’s structure. Learning effective representations from these heterogeneous information networks can help capture the users’ intention and preferences therefore improving recommendation performance. We propose a hierarchical users’ intention and preference modeling for Sequential Recommendation based on relation-aware heterogeneous information network embedding. We firstly construct a multi-relational semantic space of heterogeneous information networks to learn node embedding based on specific relations. We then model users’ intentions and preferences using hierarchical trees. Finally, we leverage the structured decision patterns to learn users’ preferences and thereafter make recommendations. To demonstrate the effectiveness of our proposed model, we also report on the conducted experiments on three real datasets. The results demonstrated that our model achieves significant improvements in Recall and MRR metrics compared to other baselines.
Keywords:
Recommender System; Sequential Recommendation; Heterogeneous Information Networks; User Intention Modeling.
1. Introduction
One of the critical tasks in the recommender system is to help users find the items that they are interested in from many items, and this will improve the user experience. Traditional recommendation algorithms usually use a binary relation between the user and item to learn users’ preferences for recommendation, such as collaborative filtering [1, 2] recommending items to users based on user or item similarity, matrix factorization [1, 3] decomposing scoring matrix into latent feature expression of users and items and then recommending items of interest to each user. However, they all have problems such as sparse matrix, cold start, flattening preference, limiting the model’s performance. There is a natural interaction process in the actual user’s purchase behavior [4]: first, the user intends to buy a specific type of item (for example, a jacket), and then driven by this intention, they select a particular item (jacket of a specific brand or a specific color) based on their preference and availability. This purchase behavior coincides with cognitive studies [52, 53] where preference only emerges one has an intention and that intention can be fulfilled with multiple options. The traditional recommendation algorithms use the user-item binary interaction relationship, ignoring the origin and the driving of the preference that is user’s intention. This is because modeling user’s intention and preference is challenging. The existing recommender systems contain a wealth of different types of information, which constitutes a heterogeneous information network [5]. Heterogeneous information networks generally have nodes and links in the form of nodes and links, which reflect different semantic perspectives on user preference [6]. The model in Sun et al. [8] use matrix decomposition and factorization machine to learn the feature expression of users and items in different meta paths. It can only learn better for specific meta paths because the model has different learning abilities depending on the meta paths. Chang et al. [9] construct a heterogeneous information network model, such as defining a network model on Yelp dataset through node types user, review, word, Etc. A proposal was then to define the semantic information association between two nodes located on two different meta paths using the PathSim algorithm. Prabhu et al. [10] propose a method to learn the feature representation of various types of nodes by deep heterogeneous network embedding. The model uses a Convolutional Neural Network and fully connected layer to learn the embedding of images and text.
However, the above-mentioned methods have four shortcomings: 1) When modeling user preferences using a binary relationship between a user and an item, the assumption is that the user’s preferences are flat, ignoring the hierarchical relationship between user intentions and preferences. 2) Identifying semantic heterogeneity between various types of nodes and relationships is difficult when modeling them in a shared feature space. 3) Fine-grained learning of node representation based on particular relationships does not quite exist. 4) Distinct link relationships may correlate to different features of node properties. In this paper, based on relation-aware heterogeneous information network embedding, we propose hierarchical intention and preference modeling for Sequential Recommendation. We make the nodes that hold the relationship close to each other and the nodes that weakly hold or do not hold the relationship far away by projecting each relationship and corresponding node in the heterogeneous information network into the relationship specific semantic space rather than the public space. To integrate disparate information, we create a relation-aware attention layer that personalizes the influence of different connections on node representation learning. We model hierarchical user intention and preference based on multi-relational node embedding learned in a heterogeneous information network. We adopt high-level user-category decision-making to understand users’ category intention and specific preferences within the intention. The model ranks and recommends items depending on their learned preference degree which is explainable. Our contributions mainly include the following four aspects: 1) We apply relation-aware heterogeneous information network embedding to generate distinct node embedding that has diverse relationships among user-item-category. 2) We propose a relation-aware attention mechanism to learn the varied effects of different relationships on the representation of distinct node features. 3) We construct a hierarchical tree of user intention and infer the possible user intentions and preferences. 4) We evaluate our method on three real-world datasets, and the results demonstrate that the proposed model outperforms the baseline methods. This paper is organized as follows: section 2 reviews related work which leads to our proposed model in sections 3; section 4 details experiments and discussions followed by conclusions.
2. Related Work
HINE-based Recommendation.
As opposed to homogeneous networks, heterogeneous information networks have multiple types of nodes and edges. Several attempts with HIN embedding have yielded promising results in various tasks [11, 12, 13, 14]. The recommender system based on heterogeneous information network successfully solves the problem of how to model different kinds of heterogeneous auxiliary information and user interaction behavior. It effectively alleviates the problem of data sparsity and cold start in the recommendation system and can significantly improve the interpretability of the recommender system. The fundamental of a recommender system based on a heterogeneous information network is to model the user-item interaction and all auxiliary information into the heterogeneous information network, and then design a recommendation model suitable for the heterogeneous information network [7]. SemRec [15] takes into account the attribute values of links, learns the weight mechanism of different meta paths, combines these similarities and approximates the scoring matrix. HeteRec [16] uses a meta path to calculate the item-item similarity, then makes an inner product with a user scoring matrix to generate a user preference diffusion matrix, and uses a non-negative matrix on the diffusion matrix to learn potential characteristics of users and items. HIN2Vec [12] learns HIN embeddings by performing several prediction training tasks concurrently. HERec [14] filters node sequences with type restrictions, capturing the semantics of HINs.
Sequential Recommendation.
In contrast to traditional recommendation approaches such as collaborative filtering [17, 18, 19], or matrix factorization [3, 20], sequential recommendation aims to capture the temporal shifting patterns of user preferences. The majority of classical approaches are based on MCs, which explore how to extract sequential patterns to learn users’ following preferences using probabilistic decision-tree models [21, 22, 23, 24]. Nevertheless, MC-based approaches can only represent local sequential patterns between neighboring interactions and cannot address the whole series. Then successive recommendation algorithms based on Factorization Machines are applied. For instance, Rendle et al. [21] present FPMC, which combines matrix factorization and the Markov model to simulate individualized transition probability. Cheng et al. [26] expand FPMC to PFMC-LR and use a Markov model to provide geographical limits to the user’s movement range. The enormous success of Deep Neural Networks also has spurred the use of deep models in sequential recommendation [27, 28, 29]. For example, Wang et al. [30] integrate auxiliary and ID information to develop e-commerce recommendations to prevent the recommender system’s cold start. Wang et al. [31] introduce HRM—Hierarchical Representation Model, which can extract interest representations more effectively from user behavior sequences. Recently, RNNs have been devised to model variable-length sequential data with the goal of encoding previous user behaviors into latent representations. Hidasi et al. [32], particularly, use Gated Recurrent Units to collect user behavior sequences for session-based recommendations, and they subsequently suggest an enhanced version [33] with a different loss function. Liu et al. [34] and others [35, 36] investigate the challenge of Sequential Recommendation given contextual information. Furthermore, unidirectional [27] and bidirectional [28] self-attention techniques are used to collect sequential patterns of user activities, resulting in state-of-the-art performance. Nevertheless, these approaches only focus on modeling the relationships between the target user’s prior behaviors and their upcoming behavior, leaving out the capacity to capture user intents buried in the behaviors. As a result, conventional techniques are unable to comprehend why the target user makes her following action.
Intention-aware Recommendation.
In recent years, diverse intention-aware recommendation has drawn great attention. It takes into account users’ intents in behavior modeling. Zhu et al. [37] propose a key-array memory network (KA-MemNN) that portrays intents directly using items’ categories in users’ behaviors. This approach is straightforward and provides an obvious way to define user intents. Chen et al. [38] employ an attention mechanism to capture users’ category-wise intentions, represented by a pair of action types and item categories. Wang et al. [39] propose a neural intention-driven method for modeling the heterogeneous intentions underlying users’ complex behaviors. Li et al. [40] present an intention-aware method to capture each user’s underlying intentions that may lead to her following consumption behavior and improving recommendation performance. Wang et al. [41] aggregate the history sequence into relation-specific embeddings to model dynamic impacts of historical relational interactions on user intention. On the other hand, they give less attention to simulating user intentions, particularly when users’ behaviors are melting. They also disregard organized user intent transition, resulting in a solid inductive bias for Sequential Recommendation.
Attention Mechanism-based Recommendation.
Deep learning’s attention process [31] is comparable to humans’ selective visual attention mechanism. Its purpose is to swiftly find more relevant information to the task goal among a significant volume of information. It is frequently used in text translation, sequence modeling, image recognition, video description, etc. Bahdanau et al. [32] pioneered the attention mechanism for machine translation within the Encoder-Decoder architecture. It can discover the shortest path between any two points, regardless of their distance or order. Deep Interest Network (DIN) [42] model calculates the correlation between users’ previous shopping histories and potential items using the attention mechanism. On the other hand, the DIN model does not take into account the time of user behavior and assumes that user behavior is independent of each other. Deep Interest Evolution Network (DIEN) [43] holds that user interest is dynamic and shifts over time. A user interest extraction layer and a user interest evolution layer are presented based on DIN. Local activation is incorporated in each stage of GRU to boost the representation of relevant interests and mimic the movement of interests indicated by users in the behavior sequence. Deep Session Interest Network (DSIN) [44] argues that the user behavior sequence has a hierarchical structure. User behavior in a single session is similar, and user behavior in subsequent sessions is considerably different. With high interpretability, the attention mechanism may distinguish the value of user behavior and screen out behaviors that are strongly related but irrelevant to objectives.
As we can see from above that awareness of the drawbacks associated with the traditional recommendation approach stimulates various of efforts in different directions. HINE-based Recommendation tries to overcome problems with homogeneous networks; Sequential recommendation aims to capture the temporal shifting patterns of user preferences. Realizing the root of the preference comes by the user’s’ intention, many efforts have been conducted to capture the user’s intention. Intention-aware Recommendation simply tries to directly link user intents with behavior which ignores the behaviors conflict and intents transitions. Recent development on Machine Learning and Deep Learning shed new lights on the problem, Attention Mechanism-based Recommendation is a brave attempt. Deep Interest Evolution Network and Deep Session Interest Network are examples. However, neither explicitly represents users’ intention and preference in a hierarchical structure. To address the issues identified, we propose a hierarchical user intention and preference framework for Sequential Recommendation based on relation-aware heterogeneous information network embedding as descripted in the following section.
3. Methodology
In this section, we first introduce the problem formalization. Then we describe the proposed model framework in detail. After that, we talk about the different modules of our model. Finally, we discuss the model training.
3.1 Problem Definition
Definition 1. Heterogeneous Information Network. A HIN is defined as a graph G=(V,E,R,ϕ,φ), in which V, E, and R are the sets of nodes, edges, and edge types, respectively. V contains the set of users U, the set of items I, and the set of categories C. Definition 2. Node and Relation. We defined three types of nodes in HIN as follows: user nodes u∈U, item nodes i∈I, category nodes c∈C. Besides, three types of relations are defined as follows: user-item (u–i), item-category (i–c), user-user (u–u). A node relation triple 〈u,r,i〉∈P, describes that two nodes u and v are connected by a relation r∈R. Here, P represents the set of all node-relation triples. Definition 3. Heterogeneous Information Network Embedding. Given a HIN G=(V,E,R,ϕ,φ), HIN embedding aims to develop a mapping function f:V→ R^d that projects each node v∈V to a low-dimensional vector in R^d, where d≪|V|.
3.2 Model Framework
The framework of our approach is shown in Figure 1. It consists of three modules as follows: (1) Relation-aware Node Embedding: We generate distinct node embedding in heterogeneous information networks that have diverse relationships among the user-item-category. The user-item relationship represents the interaction between the user and item. Meanwhile, the item-category relationship represents which category the item belongs to. Relation-aware node embedding is to develop mapping functions that project nodes of diverse relationships to low-dimensional vectors.
(2) Relation-aware Attention layer: As the core of the attention model, the relational attention layer can capture the dependencies between nodes. In order to capture the effects of different relations on different node embeddings, we create the user-specific representation of categories as a sum of the node embeddings weighted.
(3) Hierarchical User Intention and Preference for Sequential Recommendation: We construct a hierarchical tree of user intention and infer the possible user intentions and preferences the next time. We extract information about user intent from the relational attention layer and represent their hierarchical structure from fine to coarse. The users’ intentions are learned to anticipate the interactions between users and items. We elaborate on the details of the three modules in the following subsections.
3.3 Relation-aware Node Embedding
The observable node V is embedded through the embedding layer W_v∈R^(d×|V| ) to obtain low-dimensional embedding v∈R^d. For observable triples 〈u,r,i〉∈P, it represents that there is an edge r connecting between node u and node i, and edge r can also be called relation. We project it into the corresponding relation r semantic space. In the relation r semantic space, node u and node i are represented as u^r=uM_r∈R^(d_r ),i^r=iM_r∈R^(d_r ) after matrix M_r∈R^(d×d_r ) mapping, where d_r represents the embedding dimension in relation r semantic space. The correlation of two nodes is measured by Euclidean distance. Euclidean distance satisfies the triangular inequality, naturally maintaining the first-order and second-order correlation. This specific relation projection can keep the related nodes closely connected with each other or keep the unconnected nodes away. The distance between node u and node i in relation r space is: dist(u,i,r)=‖u^r+r-i^r ‖_2^2 (1) where r=rW_r∈R^(d_r ) represents the embedding vector of relation r, and r∈R^|R| is on-hot vector of relation r. W_r∈R^(d_r×|R| ) is the learnable parameter in the model. If dist(u,i,r) is small, the relation r between node u and node i is strong. On the contrary, the relation r between node u and node i is weak or there is no relation r.
3.4 Relation-aware Attention layer
Different relations have different semantic information. That is, they represent different aspects of nodes. This section wants to capture the effects of different relations on different node embeddings. We propose a relation-aware attention layer to learn to assign different attention weights to capture the relationships among the nodes. We input node embedding v∈V into the attention layer, one layer can be formulated as follows: h=∑_r^R▒ ω_r v^r,ω_r=exp(q^T σ(W_a v^r+b_a ))/(∑_k^R▒ exp(q^T σ(W_a v^k+b_a )) ) (2) where ω_r represents the attention weight of relation r embedded in nodes v∈V, and W_a∈R^(d×d_r ), q∈R^d, and b_a∈R^d are learnable parameters in the model. Finally, we get the final feature representation h of node v, which combines node embedding v∈V based on multi-relation semantics. Specifically, user type node u, item type node i and category type node c correspond to h_u, h_i and h_c respectively.
3.5 Hierarchical User Intention and Preference for Sequential Recommendation
Inspired by PRABHU et al. [10] and Zhu et al. [25], we build a hierarchical tree according to the characteristic that the category-item relation has a hierarchical index in the recommender system. The retrieval process of each hierarchy is called hierarchical user intention and preference. To facilitate construction, at each hierarchy of non-leaf nodes in the tree, we first randomly sort the category information and place the items together which belong to the same category. If an item belongs to multiple categories, it will be randomly assigned to one of them. Then we use the learned node embedding vector to re-cluster into a new tree. The non-leaf node is a coarse-grained category concept used as the index of items in the tree. The leaf node is the items in the corpus, which finely represents users’ specific preferences under their intention. We predict the user’s category intention and preference as follows: s_uc=σ(h_u^T H_c ) (3) where, H_c=[h_(c_x ) ](x=1)^(|C|)∈R^(d×|C|) is category feature representation, and s_uc can also be written as s_uc=[s(uc_x ) ](x=1)^|C| . Here, the value of s(uc_x ) reflects the user u’s preference for category c_x, and σ is sigmoid activation function. We take the items {i_(1,) i_(2,) i_(3,)∙∙∙i_N } which are the first K categories according to users’ interest as the candidate set. The feature of this candidate set is represented as H_i=[h_(i_x ) ](x=1)^N∈R^(d×N), and then the user’s preference for these candidate items is calculated based on user’s category intention as follows: s_ui=softmax(h_u^T H_i ) (4) where softmax() is a normalization function. s_ui=[s(ui_x ) ](x=1)^N, s(ui_x ) represents the probability that user u likes item i_x. We rank the probabilities in s_ui and recommend the top k items to user u.
3.6 Model Training
We use Bayesian personalized ranking objective [45] to optimize our model. The key idea of Bayesian personalized ranking optimization is to make the items that users are really interested in ranking ahead of the items that users are not interested, that is, the positive sample probability is greater than the negative sample probability. SoSo, we take a negative sample i_(x^’ ) for each positive sample (u,i_x )∈D_train^+. When optimizing node embedding in a relation semantic space, for the observable triple 〈u,r,i〉∈P\D_test^+, we take a negative sample i^’, indicating no relation r between i^’ and u. We hope that u is closer to positive sample i and farther away from negative sample i^’. Our optimization objectives are: L=argmin-∑((u,i_x )∈D_train^+,i(x^’ ))▒lnσ(s_(ui_x )-s_(ui_(x^’ ) ) ) -∑(〈u,r,i〉∈P\D_test^+,i^’)▒lnσ(‖uM_r+r-iM_r ‖_2^2-‖uM_r+r-i^’ M_r ‖_2^2 ) +λ_1 ‖W* ‖2^2+λ_2 ‖q‖_2^2+λ_3 ∑(r∈R)▒‖M_r ‖2^2 (5) where λ_1, λ_2 and λ_3 are the regularization parameter. We use the Adam method [46] to optimize our model. W*={W_v,W_r,W_a } and q are learnable parameters in our model.
4 Experiments
We provide empirical results to demonstrate the effectiveness of our proposed model. The experiments are designed to answer the following research questions: RQ1: How does our proposed model perform compared with other state-of-the-art sequential recommendation models and user intention modeling-based methods? RQ2: How does each module (i.e., multi-relation HIN embedding, Relation-aware Attention layer, and hierarchical user intention) affect the performance of our model? RQ3: How do the influences of different parameters affect our proposed model?
4.1 Experiments settings
To answer the first research question (RQ1), we use three actual and available datasets and make comparisons with existing models on Recall and MRR.
4.1.1 Datasets In order to evaluate our proposed model, we conducted extensive experiments on the three real datasets. The statistics of the datasets are summarized in Table 1. MovieLens: This dataset is about movie ratings and has been widely used to evaluate recommendation algorithms. We use ML-1m containing 1 million rating records, respectively. We extract interaction records from rating data, items from “movie name”, and users from “user id”. Double Book: This dataset is about book ratings collected from Douban website. We use friend relationship, rating data, and genres of books in the dataset as category. It is worth noting that although our model only illustrates three types of nodes, our model can be extended to more types of nodes and correspond more types of relationships. Last-FM: This dataset is about music that users listen to on the online music website Last.fm. The dataset includes friend relationship, user listening to artist, user label to artist, and artist label. In order to unify category nodes, we take the artist’s label as category.
4.1.2 Evaluation Metrics In order to evaluate the recommendation performance of our proposed model, we use two evaluation metrics Recall@K and Mean Reciprocal Rank (MRR@K for short). The first metric evaluates the fraction of ground truth items that are retrieved over the total amount of ground truth items, while the second metric is the mean of reciprocal of the rank at which the ground-truth item is retrieved. The larger the values of both Recall and MRR metrics, the better the performance. “Recall@” K=1/|D_test^+ | ∑((u,i_x,r)∈D_test^+)▒ I(p(u,x)⩽k) (6) “MRR@” K=1/|D_test^+ | ∑((u,i_x,r)∈D_test^+)▒ 1/R(u,x) I(p_(u,x)⩽k) (7) where p_(u,x) represents the ranking of the positive sample i_x among the top k items recommendation for user u. Ι(⋅) indicates that if the positive sample i_x is in the top k items, it returns 1; otherwise it returns 0. D_test^+ is the test set.
4.1.3 Baselines We compare our model with the following baseline algorithms, including heterogeneous information network embedding methods, session-based recommendation, and hierarchical representation approaches. DHA (Deep Heterogeneous Autoencoders) [47]: This paper proposes a deep heterogeneous self-encoder to model heterogeneous auxiliary information to solve the data sparsity problem of the collaborative filtering algorithm. We set the number of hidden layers of DHA self-encoder L = 4. We also sort the input data of DHA according to the data format requirements in this paper. The input data include user, item, category and interaction. BPR-MF + TransE [48]: this method combines BPR-MF and TransE. BPR-MF combines Bayesian personalized ranking with matrix factorization model and learns personalized ranking from implicit feedback. TransE models the node embedding of heterogeneous information network. Because we do not use image data, we remove the image (visual knowledge) processing module in BPR-MF + TransE. FPMC [21]. This method models user preferences by combining MF, which captures users’ general preferences and a first-order MC to predict the user’s next action. PRP (PageRank with Priors) [49]: This method integrates the user-item relationship and other heterogeneous auxiliary information into a unified isomorphism diagram. PageRank outputs a personalized initial probability distribution. Similarly, we remove the image (visual knowledge) processing module in PRP. FOSSIL [24]. This method integrates factored item similarity with MC to model a user’s long- and short-term preferences. We set μ_u and μ as single scalar since the length of each session is variable. HRM [31]. This method generates a hierarchical user representation to capture sequential information and general tastes. We use max pooling as the aggregation operation because this achieves the best result. SHAN [50]. This model employs two attention networks to mine users’ long- and short-term preferences. KA-MemNN [37]: This paper proposes a key-array memory network to hierarchize user intention preference for sequence recommendation based on the ternary relationship of user-intention-item.
4.1.4 Parameter Settings In order to facilitate the experiments, we filter out users and items for which interactive data are less than 5. For each user, we randomly select 80% of the interactive data as the training set D_train^+ and the remaining 20% of the interactive data as the test set D_test^+. In the training set, we randomly selected 20% of the interactive data as the development set D_valid^+ to adjust our model parameters and comparison methods. In addition, models are tuned for best performance through tuning of parameters, such as learning rate α∈{0.1,0.01,0.001,0.0001}, regularization parameters λ_*∈{0.1,0.01,0.001,0.0001}, Dropout∈{0.2,0.4,0.5}, and dimensionality d=d_r∈{60,80,100,120,140,150}.
4.2 Performance Comparison
We begin with the comparison with respect to Recall@20, Recall@50, MRR@20 and MRR@50. Table 2 shows the empirical results, with percent Imp. denoting the relative improvements of the top performing technique (bold) over the strongest baselines (underlined). We find that: Our model consistently outperforms all baselines across the three datasets in terms of all measures. More specifically, it achieves significant improvements over the strongest baselines with respect to MRR@20 by 7.25%, 25.7%, and 15.87% in MovieLens, Douban-Book, and Last-FM, respectively. Our model’s logic and efficacy are demonstrated in this way. These gains can be attributed to our model’s relational modeling: (1) By investigating user intentions, we can better define the links between users and objects, resulting in more effective user and item representations. Some baselines, on the other hand, ignore hidden user intents; (2) our model learns node embeddings in heterogeneous information networks based on user-intention-item relationships; (3) our model fuses node feature representations in multi-relational semantic spaces using relation-aware attentional layers. We can see that the sequential methods (e.g., FPMC, HRM, and KA-MemNN) outperform the non-sequential methods (e.g., BPR-MF, PRP and FOSSIL) in general. The methods that only consider user actions without the sequential order do not make full use of the sequence information and report the worse performance. Specifically, compared with BPR-MF, the main advantage of FPMC comes from modeling historical user actions with first-order Markov chains, namely considering the sequence order, so that FPMC reports better results than BPR-MF. This can verify that sequential pattern is essential for improving the predictive ability for sequential recommendations. BPRMF+TransE and PRP outperform DHA, indicating that heterogeneous information network embedding can more reasonably capture heterogeneous information semantic features to improve recommendation quality rather than directly encoding structural information in a feature engineering manner. KA-MemNN outperforms both BPR-MF+TransE and FPMC on all the datasets, indicating that hierarchical user intent and preference are better than flat user preference of the learning approach. Compared with BPRMF+TransE and KA-MemNN, we model the heterogeneity of relationships in heterogeneous information networks based on specific relation semantics and personalize the fusion of node feature representations in each semantic space, and in addition, we model hierarchical user intentions and preferences according to the natural user interaction process. As the data show, there is a discrepancy in performance between HRM and KA-MemNN. The disparity, we believe, is caused by the various degrees of user intentions. When compared to single-level user intentions, two-level intents may be thought of as an extension that separates user intents into particular and broad categories.
4.3 Impact of Components
In this section, we will drill deeper to answer question RQ2 that the impact of each component in our proposed model in relation with the overall performance based on embedding the public feature space. We also want to verify that our hierarchical user intent and preferences outperform flat user preferences on recommendation. We adopt three simplified versions of HIP-RHINE as follows. HIP-RHINE-1: remove the relation-aware heterogeneous information embedding module, and the replacement operation is to integrate heterogeneous relations and structured data into a unified isomorphic graph. HIP-RHINE-2: remove the relation-aware attention layer module, and the replacement operation is to directly add the feature expressions of nodes in each relation semantic embedding space point by point. HIP-RHINE-3: remove the hierarchical tree module, and the replacement operation is to directly calculate s_ux for the whole set of items and recommend by ranking. We also apply Recall@N and MRR@N to evaluate the performance of these models. We show the results under the metrics of Recall@20, Recall@50, MRR@20, and MRR@50. In addition, we evaluate the score of each category as an average of the scores of its items. This way the intention-based MRR can also reflect the performance of item recommendations. The results in Table 3 show that our method performs well on all the datasets compared to HIP-RHINE-1 because we consider the heterogeneity of relations for node embedding. Besides, our method performs well on all the datasets compared to HIP-RHINE-2 because our method captures the degree of influence of different relations on the final node embedding. The experiments demonstrate the effectiveness of our multi-relational semantic embedding and relation-aware attention layer. Compared with HIP-RHINE-3, our method performs well on all datasets because our method hierarchizes user intents and predicts user preferences for items based on specific intents. The experiments show the effectiveness of hierarchical user intents and preferences.
4.4 Parameter Analysis
After analyses on individual components in relation to the model’s performance, we realize that the model’s performance is also affected by the model’s parameters. In order to further investigate the influences of different parameters in our model, we calculate the values of Recall@20, Recall@50, MRR@20, and MRR@20 for HIP-RHINE across different numbers of dimensions with size d, and also explore the sensitivity of the parameter—the number of negative samples. As shown in Figure 2(a)(b)(c)(d), the model’s performance gradually improves as dimension d increases. However, the model performance decreases a little on the Last-FM dataset when d>120 and finally stabilizes. This trend indicates that the model can capture more complex feature embeddings as d increases. However, over-increasing d may lead to overfitting problems resulting in a degradation of model performance. Furthermore, we study the effect of the sampling number k on the overall performance. Because the item sizes differ across the three datasets, we experiment with various k ranges. Specifically, we try k∈{10,20,30,40,50,60} on MovieLens, k∈{10,100,200,300,400,500} on Douban-Book, and k∈{10,50,100,150,200,250} on Last-FM, respectively. Here we only show the results on one dimension over each dataset due to space limitation. As shown in Figure 3(a)(b)(c), as the number of negative examples increases, the performance of our model first also grows. The trending is quite similar across all three datasets. The performance gain between two successive trials, on the other hand, diminishes as the sampling number k grows. It suggests that if we continue to sample more negative samples, we will see less performance progress but more computational complexity.
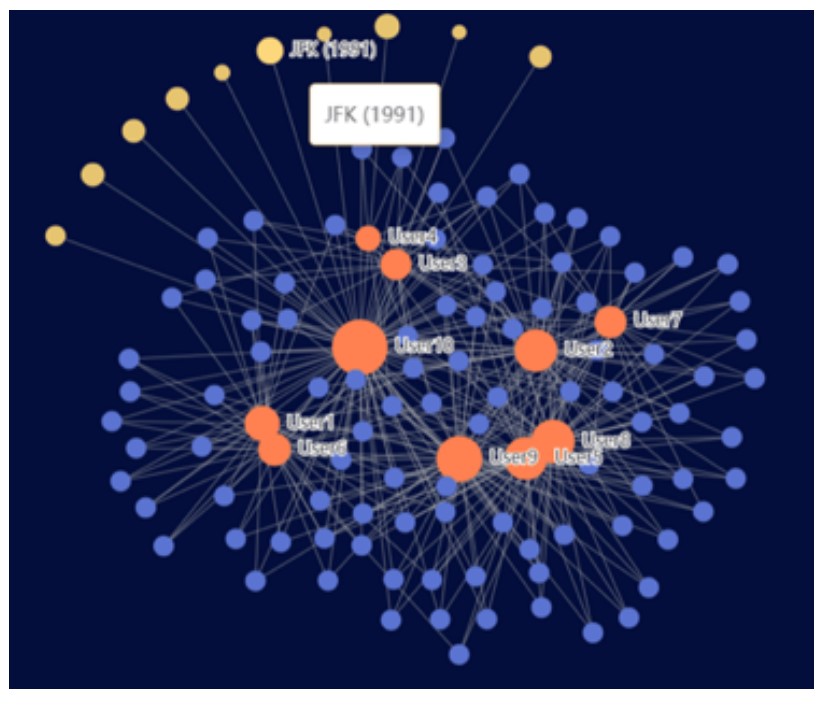
4.5 Case Study
To investigate whether our proposed model is effective and explainable, we chose one user at random from Douban-Book and visualize the hierarchical tree of user intention and preference [51,37]. We extract attention between a single category and the observe objects that correspond to that category for each user. As shown in Figure 4, there are three types of nodes. A category node is a broad term that encompasses a wide range of concepts. A concept is a collection of items that share some common attributes. Concepts, as opposed to coarse-grained categories and fine-grained entities, can assist in better representing users’ interests at a semantic granularity that is appropriate. An entity is a unique item that belongs to one or more concepts. There are three sorts of edges between nodes as well. The IsA relationship denotes that the destination node is a child of the source node. The involved relationship indicates that the destination node is involved in a source node-described item. The color scale of Entity nodes(items) shows the value of the attention weights, with darker signifying a more considerable weight and lighter representing a lower weight, as illustrated in Figure 3. When generating category embeddings, we can see that the frequently visited objects are generally given a higher weight. This phenomenon might be explained because category-specific users’ preferences are reflected in the most frequently viewed items in that category.
5 Conclusions
In this paper, we propose a model for sequential recommendation based on hierarchical intentions and preferences with relation-aware heterogeneous information network embedding, which can learn node representation in the heterogeneous information network at a fine-grained level based on the particular relationships. To customize the merging of heterogeneous information, we adopt a relation-aware attention Layer. Furthermore, we employ hierarchical trees to represent user intents and preferences hierarchically, and we use structured choice patterns of users for user preference learning to improve recommendation performance. Extensive experiments on three real datasets are carried out to evaluate the performance of our proposed approach. In terms of Recall and MRR metrics, the findings show that our model outperforms state-of-the-art approaches by a significant margin. In the future, we will investigate multiple and variable intents or knowledge graph information combined with user intention modeling.
Last updated: June 26, 2024